Over the past few months, I’ve seen growing excitement about this tool. Since I’m still facing a bit of “blank page syndrome” with these articles, I decided to give it a try for fun.
The Duck’s sauce
DuckDB is essentially an embedded database with no server component. This might sound similar to SQLite, but there are two key differences:
-
SQLite is transactional, which provides low-latency retrieval and makes it ideal for applications. By contrast, DuckDB is columnar, which allows for much faster data aggregation, making it ideal for data analysis. It processes information in a vectorised and parallelised manner, making a more effective use of the computational resources that the CPU provides.
-
DuckDB can directly query CSV and Parquet files as if they were database tables. Also, I’m surprised that there’s barely any discussion about the fact that it can also handle JSON and Excel files, and even read and write other database systems like PostgreSQL and SQLite.
The crime of using CSV files
As much as people say that “CSV is the poor man’s database”, I always argue that data analysis should be done with databases rather than plain files, and the reason for this is efficiency. When practising data analysis, you are often given CSV or Parquet files containing large datasets, which normally require a powerful computer capable of loading their entire contents. However, in most cases, you don’t actually need all the raw data. Usually, you filter and/or group the data before further analysis, which already reduces memory requirements.
The challenge with formats such as CSV and Parquet1 is that they cannot be queried like a database. DuckDB solves this limitation by allowing you to query these files using SQL, enabling far more efficient data processing. Let’s put this to the test by loading a large CSV file from this sample dataset, first using the default method in Pandas, and then with DuckDB, on a computer with a modest 16GB of RAM:
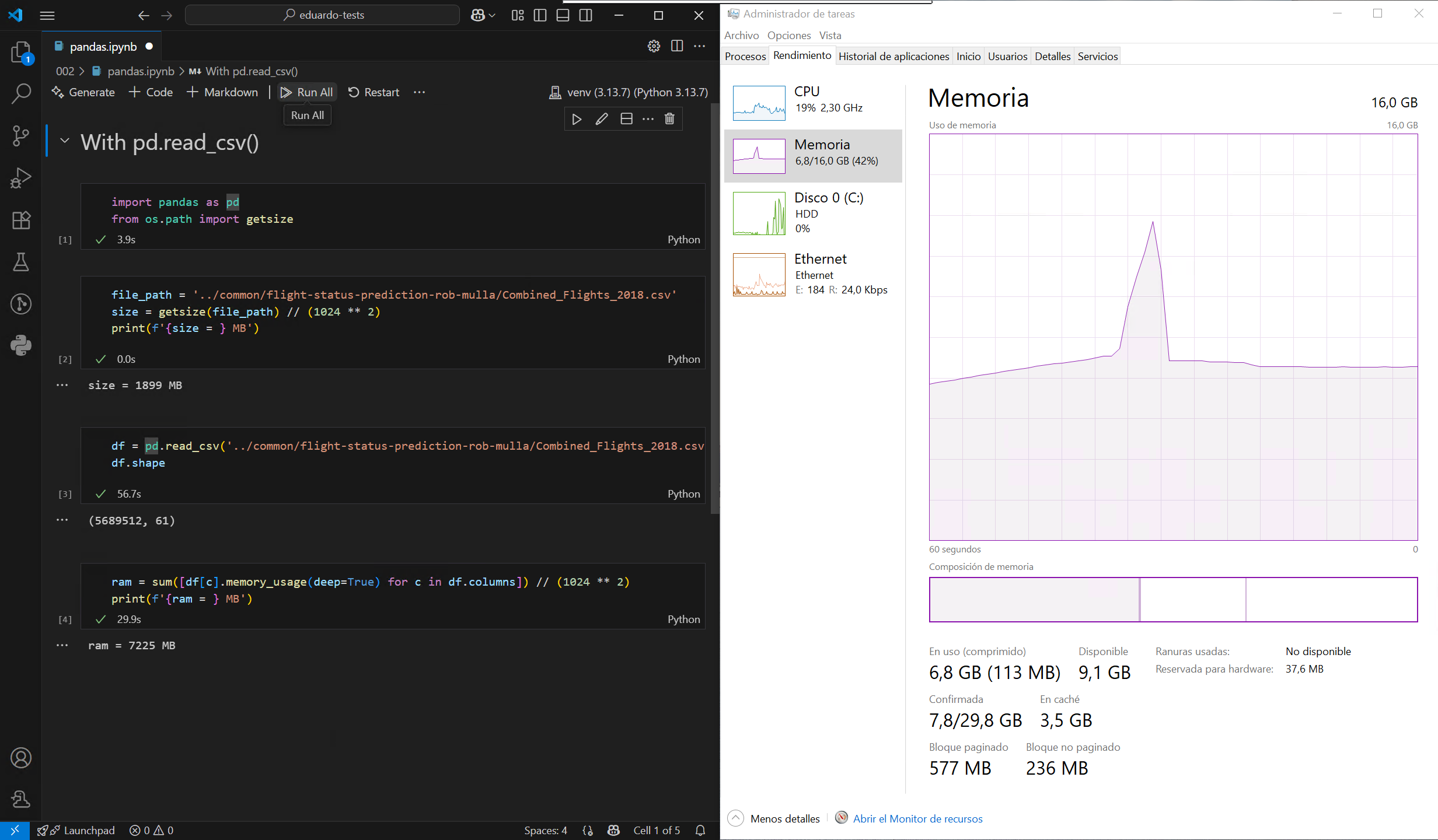
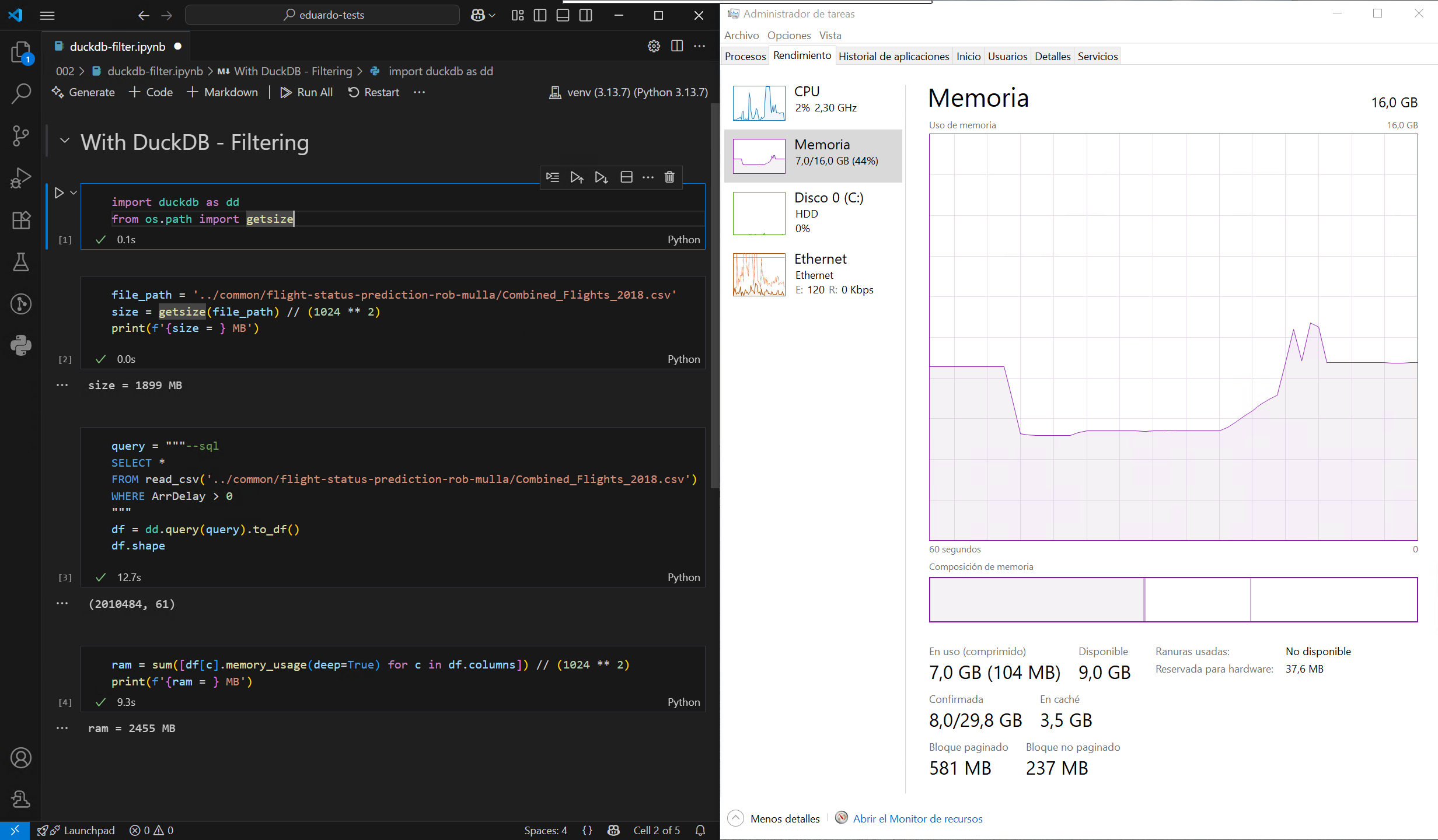
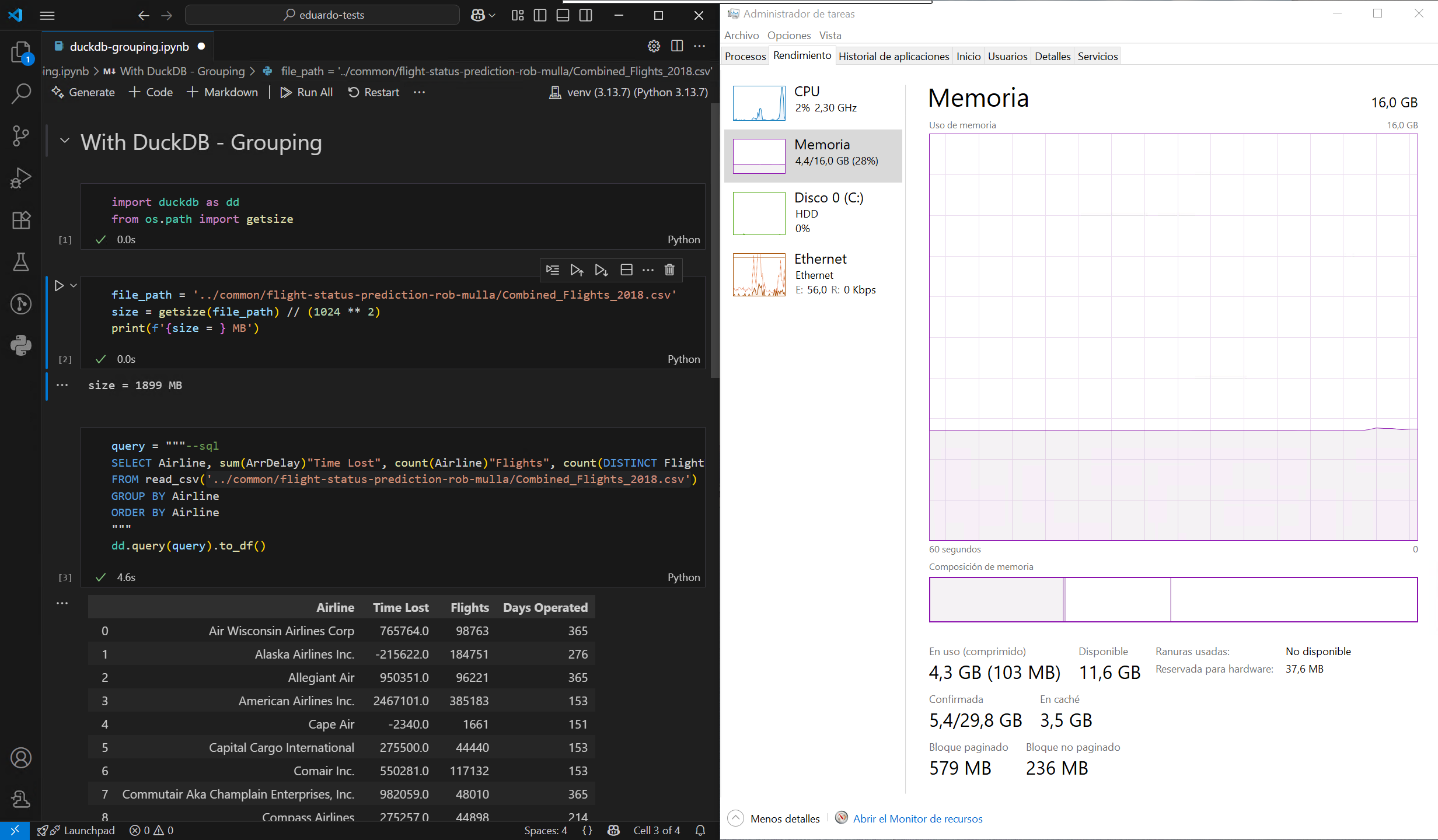
As observed, DuckDB does not need to load the entire file into memory before filtering or grouping, which significantly reducing peak memory usage. It’s also much faster, thanks largely to its highly multithreaded execution engine. Even better, DuckDB can treat multiple files as a single table, so it’s possible to load the entire dataset filtered without blowing the memory limit of my machine:
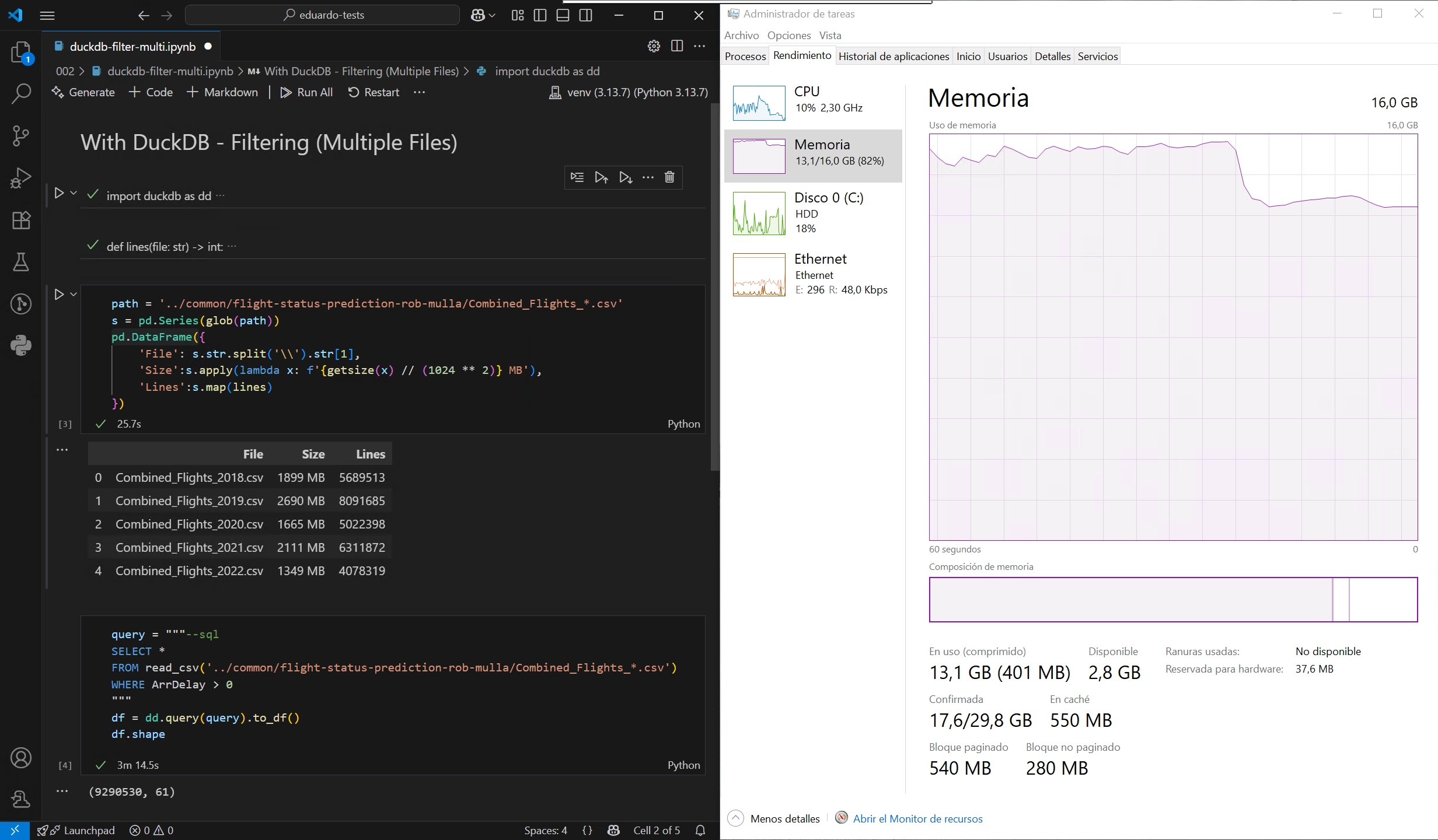
Now, while this is impressive, it’s not entirely unique: the Polars library can achieve the same through query plans. Also, it’s sometimes suggested that DuckDB, with its broad set of functions and extensions, could replace Pandas entirely for data analysis. Personally, I would never do that, as I actually dislike writing SQL. But, what happens when you don’t have access to a full Python interpreter, and the only thing available is the ability to run a SQL statement? Keep that in the back of your mind for my next article.
This Duck(DB) is a different kind of beast
Going back to real databases, I wanted to see how much of a difference DuckDB’s native format makes in practice compared to SQLite. This time, I’m importing all the years from Parquet files instead of CSVs, into two identical databases, one for each format. Crazy enough, I can do all of this with a simple Python script that uses only the DuckDB library as a dependency:
import duckdb as dd
# Parquets -> DuckDB
con = dd.connect('003/flights.duckdb')
for year in range(2018, 2019 + 1):
print(f"Importing {year}...")
f_query = "CREATE TABLE flights AS " if year == 2018 \
else "INSERT INTO flights "
con.query(f_query + f"SELECT * FROM 'common/flight-status-prediction-rob-mulla/Combined_Flights_{year}.parquet'")
print(f"Year {year} done!")
# DuckDB -> SQLite3
print(f"Duplicating to SQLite...")
con.query("""--sql
ATTACH '003/flights.sqlite3' AS sqlite_db (TYPE sqlite);
CREATE TABLE sqlite_db.flights AS SELECT * FROM flights;
""")
print(f"SQLite duplication done!")
Once I had easily built my test databases, I ran a quick test using the same query on both, and the results shocked me, as I wasn’t expecting such a massive difference:
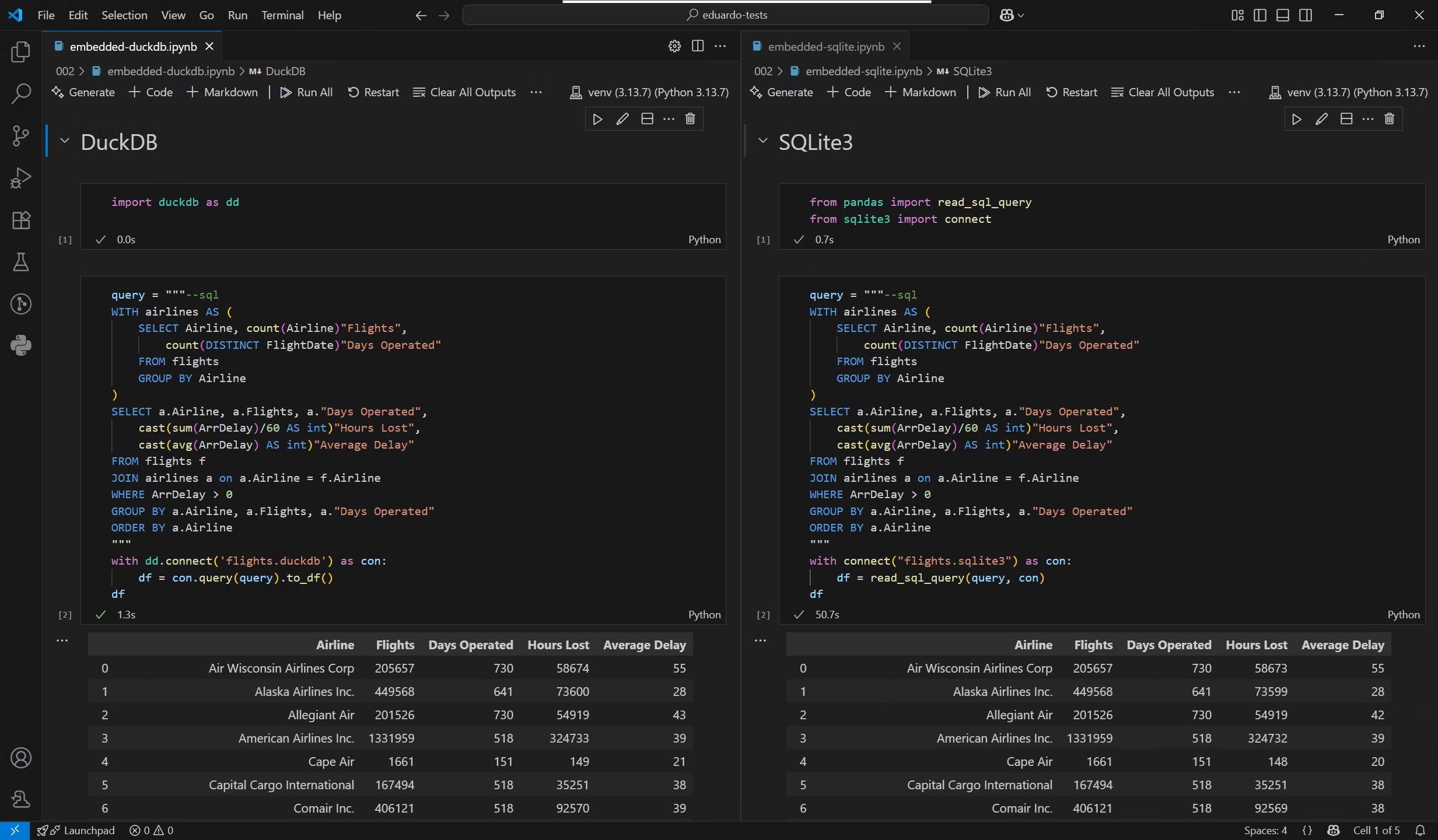
Take these results with a pinch of salt, as I’m not a Database Administrator, and I may have overlooked something on the SQLite side. Still, that alone can’t account for the huge gap I observed.
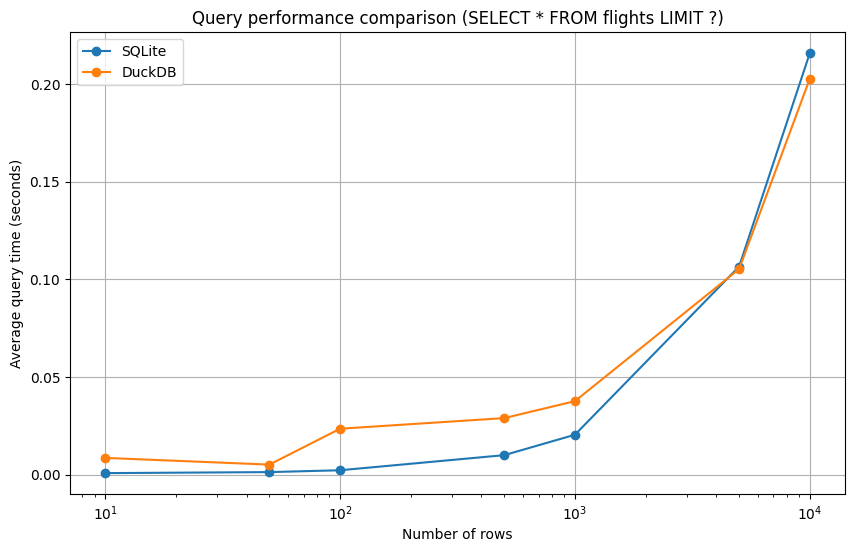
Of course, don’t rush to replace all your SQLite databases because as I mentioned earlier, which technology is best depends on your use case. For retrieving small chunks of data, SQLite is still the king, as God intended. Here’s a performance comparison with my dataset:
🎶 Ducks flying by, you know how I feel… 🎶
I could dive more into technical conclusions, and I’ve saved some cool tricks with DuckDB for the next entry. But I’d rather end on a personal note: even though I normally despise SQL and have no immediate need for DuckDB at work, experimenting with it gave me a few rare moments of genuinely enjoying writing SQL. Take that as you will.
-
Here I’m referring to Parquet files stored in a regular file system, data lakes are a different story. ↩︎