En los últimos meses, he observado un creciente interés por esta herramienta. Como todavía sufro un poco del “síndrome de la página en blanco” con estos artículos, decidí probarla por diversión.
La salsa del pato
DuckDB es esencialmente una base de datos embedded sin servidor. Esto puede parecer lo mismo que SQLite, pero hay dos diferencias clave:
-
SQLite es transaccional, lo que proporciona una recuperación de baja latencia y lo hace ideal para aplicaciones. Por el contrario, DuckDB es columnar, lo que permite una agregación de datos mucho más rápida, haciéndolo ideal para el análisis de datos. Procesa la información de forma vectorizada y paralela, lo que facilita un uso más eficaz de los recursos que proporciona la CPU.
-
DuckDB puede consultar directamente archivos CSV y Parquet como si fueran tablas en bases de datos. Además, me sorprende que apenas se hable del hecho de que también puede manejar archivos JSON y Excel, e incluso leer y escribir otros sistemas de bases de datos como PostgreSQL y SQLite.
El delito de utilizar archivos CSV
Por mucho que se diga que “El CSV es la base de datos del pobre”, yo siempre defiendo que el análisis de datos debe realizarse con bases de datos en lugar de archivos de texto plano, y la razón es la eficiencia. Cuando uno realiza análisis de datos, a menudo se reciben archivos CSV o Parquet que contienen grandes conjuntos de datos, lo que normalmente requiere un ordenador potente capaz de cargar su contenido entero. Sin embargo, en la mayoría de los casos, no se necesitan todos los datos en bruto. Por lo general, se filtran y/o agrupan los datos antes de realizar un análisis más detallado, lo que de por sí ya reduce los requisitos de memoria.
El problema con formatos como CSV y Parquet1 es que no se pueden consultar como una base de datos. DuckDB resuelve esta limitación al permitir consultar estos archivos usando SQL, lo que permite un procesamiento de datos mucho más eficiente. Pongamos esto a prueba cargando un archivo CSV de gran tamaño de este conjunto de datos de muestra, primero utilizando el método predeterminado de Pandas y, a continuación, con DuckDB, en un ordenador con unos modestos 16 GB de RAM:
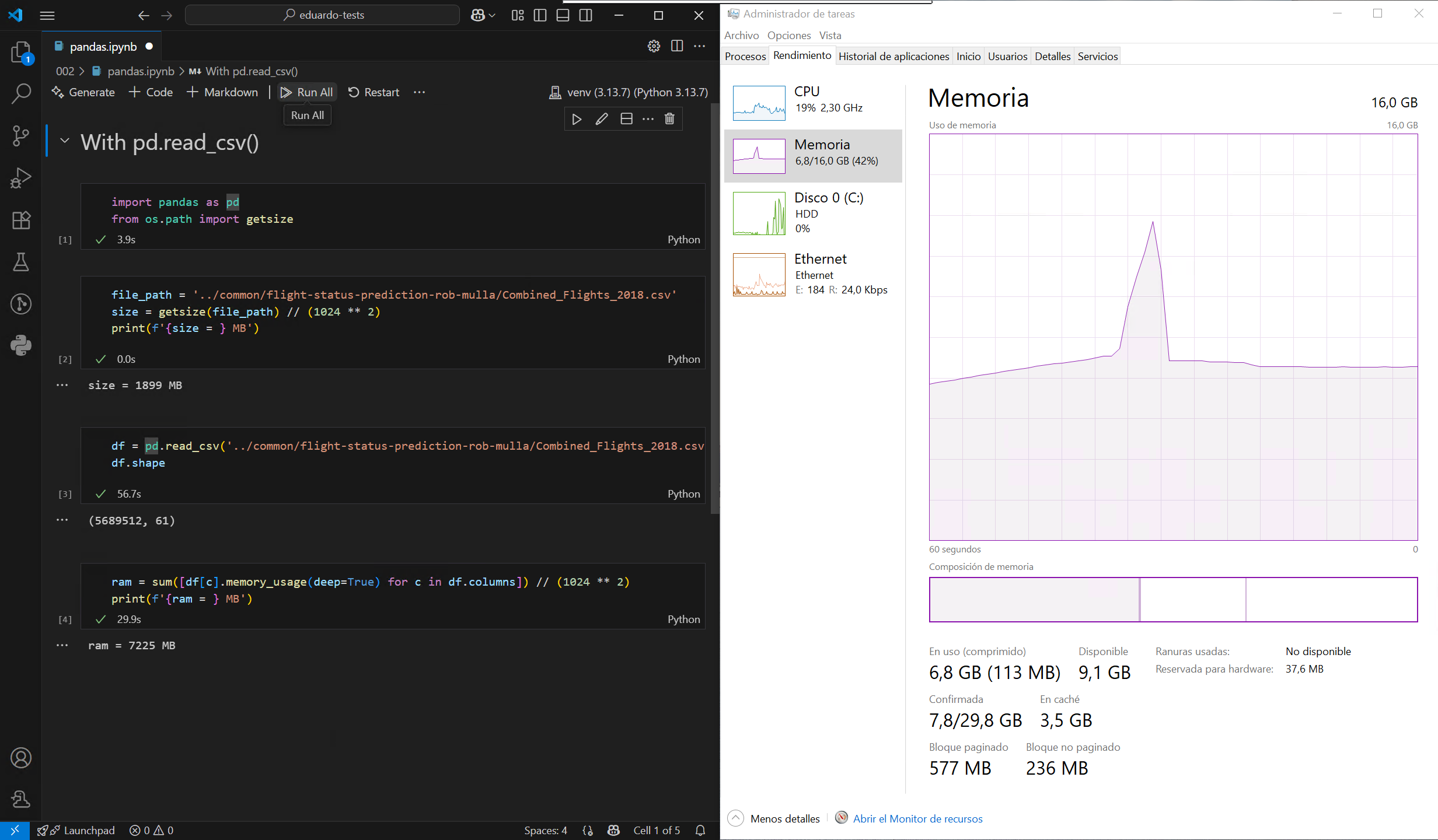
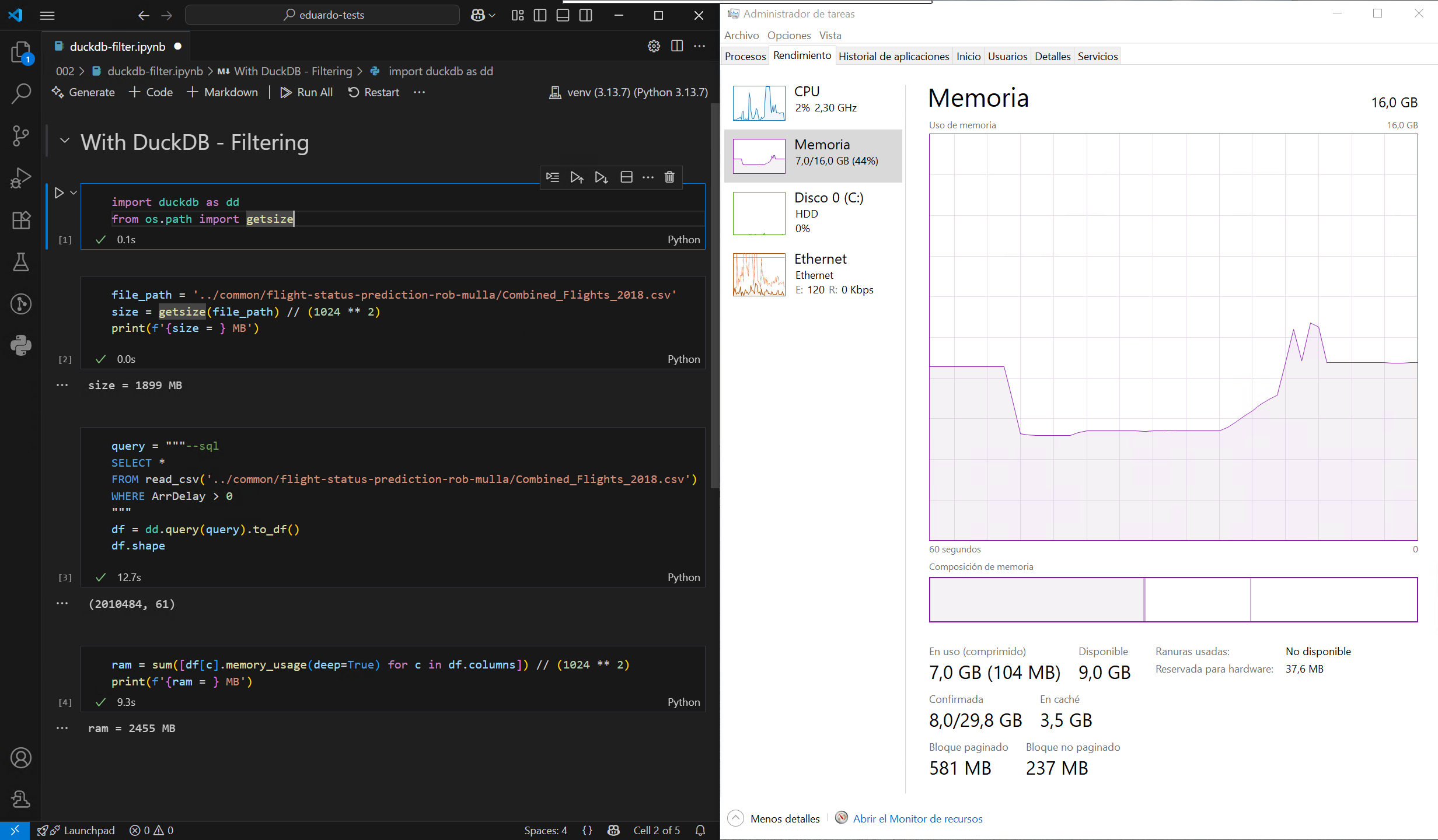
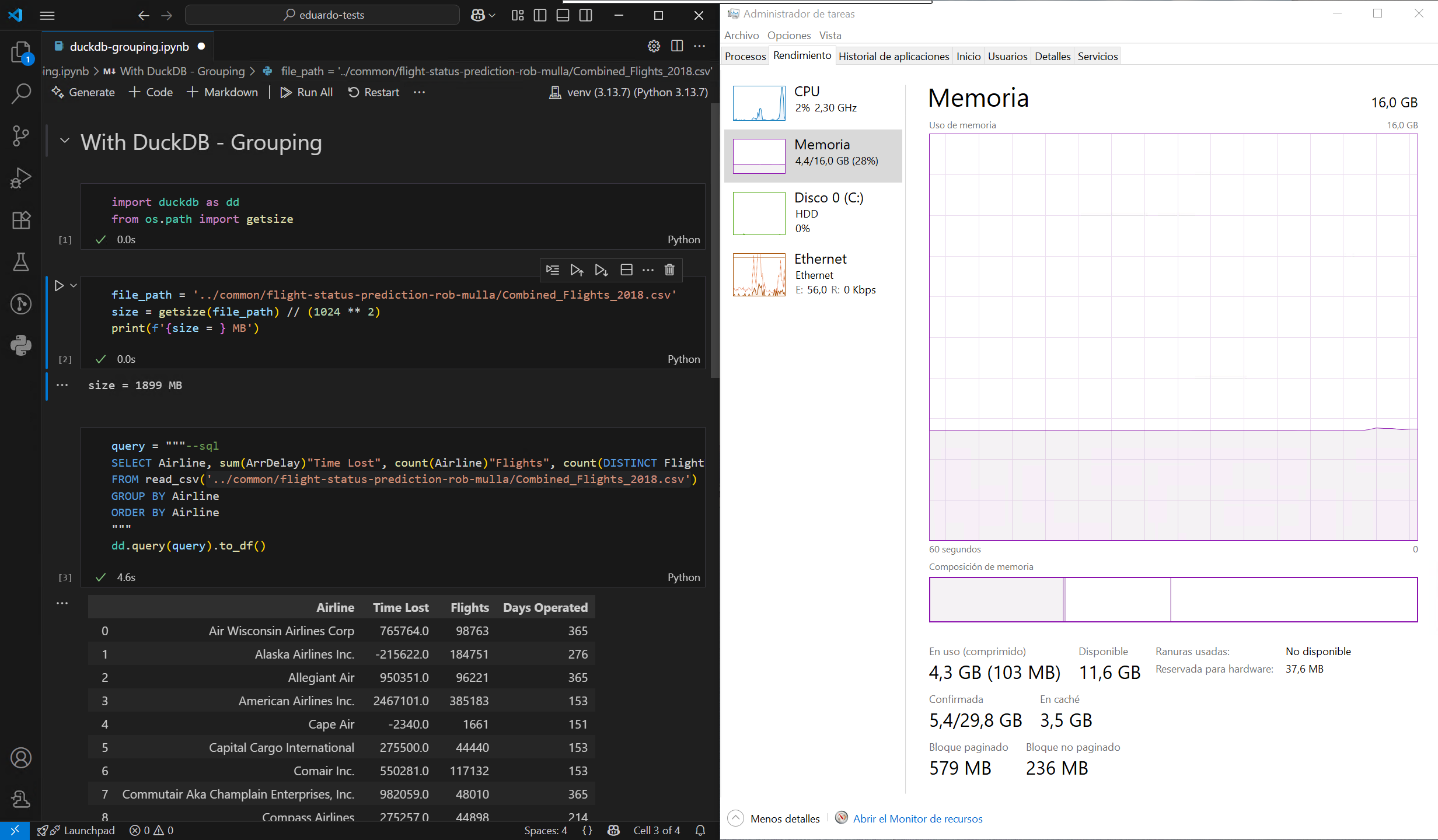
Como se puede observar, DuckDB no necesita cargar todo el archivo en la memoria antes de filtrarlo o agruparlo, lo que reduce significativamente el pico máximo de uso de memoria. También es mucho más rápido, en gran parte gracias a su motor de ejecución altamente multihilo. Aún mejor, DuckDB puede tratar varios archivos como una sola tabla, por lo que es posible cargar todo el conjunto de datos filtrado sin superar el límite de memoria de mi máquina:
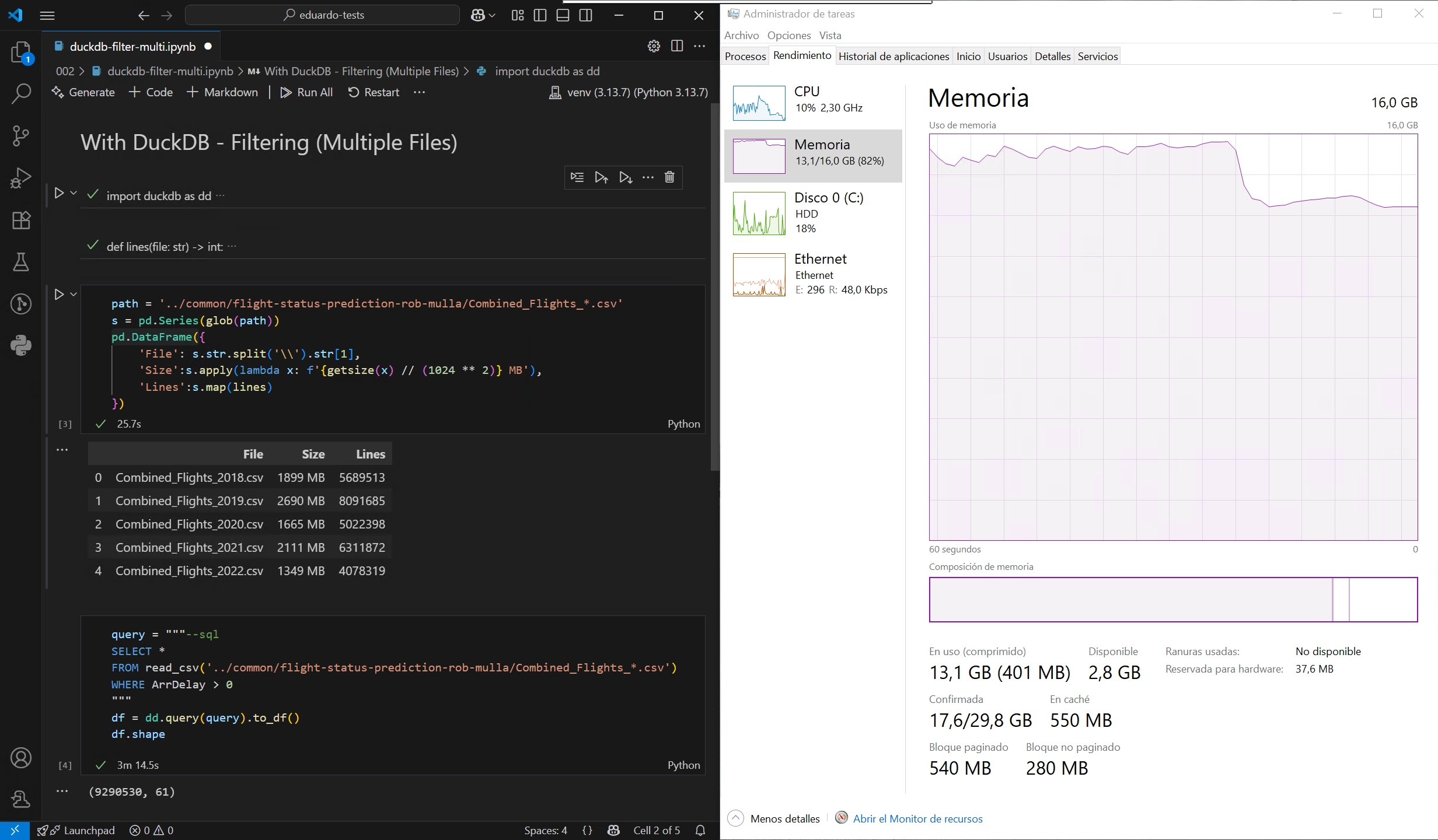
Ahora bien, aunque esto es impresionante, no es que sea precisamente único: la biblioteca Polars puede lograr lo mismo a través de query plans. Además, a veces se sugiere que DuckDB, con su amplio conjunto de funciones y extensiones, podría sustituir por completo a Pandas para análisis de datos. Personalmente, yo nunca lo haría, ya que no me gusta escribir SQL. Pero, ¿qué ocurre cuando no se tiene acceso a un intérprete de Python completo y lo único disponible es la capacidad de ejecutar una instrucción SQL? Quédate con esto en mente para mi próximo artículo.
El pato loco
Volviendo a las bases de datos de verdad, quería ver cuánta diferencia supone en la práctica el formato nativo de DuckDB en comparación con SQLite. Esta vez, estoy importando todos los años desde archivos Parquet en vez de CSVs, a dos bases de datos idénticas, una para cada formato. Por increíble que parezca, puedo hacer todo esto con un simple script de Python que solo utiliza la biblioteca de DuckDB como dependencia:
import duckdb as dd
# Parquets -> DuckDB
con = dd.connect('003/flights.duckdb')
for year in range(2018, 2019 + 1):
print(f"Importing {year}...")
f_query = "CREATE TABLE flights AS " if year == 2018 \
else "INSERT INTO flights "
con.query(f_query + f"SELECT * FROM 'common/flight-status-prediction-rob-mulla/Combined_Flights_{year}.parquet'")
print(f"Year {year} done!")
# DuckDB -> SQLite3
print(f"Duplicating to SQLite...")
con.query("""--sql
ATTACH '003/flights.sqlite3' AS sqlite_db (TYPE sqlite);
CREATE TABLE sqlite_db.flights AS SELECT * FROM flights;
""")
print(f"SQLite duplication done!")
Ahora que pude construir fácilmente mis bases de datos de prueba, realicé una prueba rápida utilizando la misma consulta en ambas, y los resultados me chocaron porque no esperaba una diferencia tan grande:
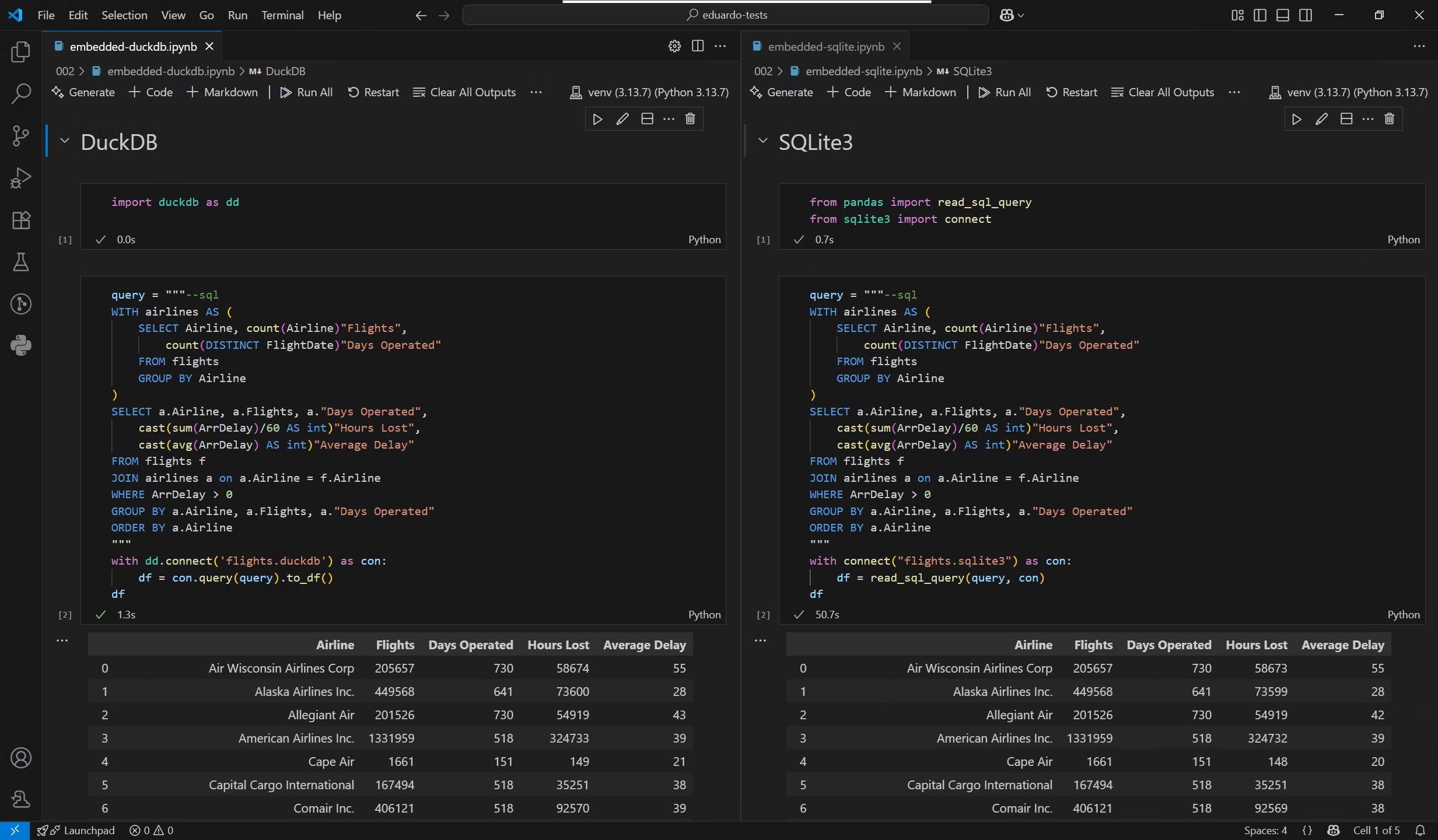
Estos resultados yo los tomaría con cautela, dado que no soy administrador de bases de datos y es posible que haya pasado por alto algo en la parte correspondiente a SQLite. Aun así, eso de por sí solo no puede explicar la enorme diferencia que observé.
Por supuesto, no te apresures a migrar todas tus bases de SQLite porque, como mencioné anteriormente, la mejor tecnología depende de tu caso de uso. Para recuperar pequeños fragmentos de datos, SQLite sigue siendo el rey, como Dios manda. Aquí tienes una comparación de rendimiento con mi conjunto de datos:
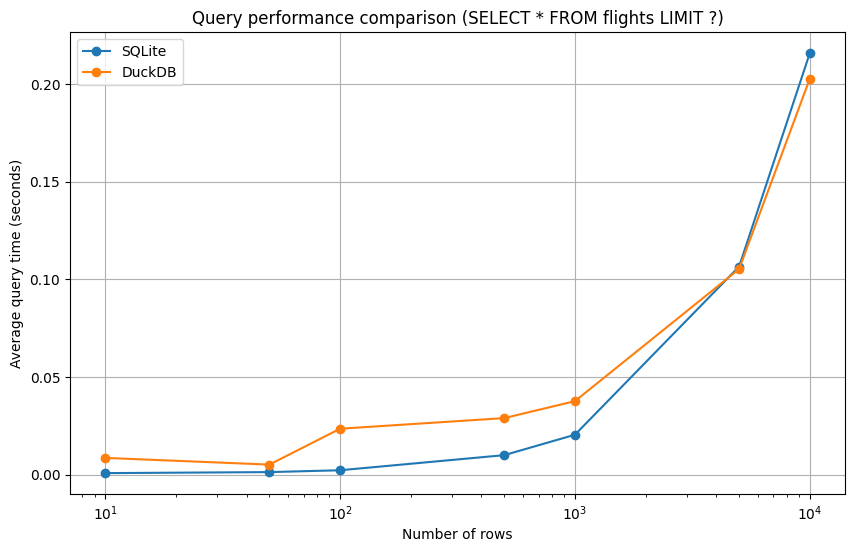
🎶 Y cien patos dónde irán, dónde irán… 🎶
Podría seguir sacando más conclusiones técnicas, y he reservado algunos trucos con DuckDB para la próxima entrada. Pero prefiero terminar con una nota personal: aunque normalmente aborrezco SQL y no tengo una necesidad inmediata de usar DuckDB en el trabajo, experimentar con él me ha proporcionado unos momentos únicos en los que de verdad he disfrutado escribiendo SQL. Dejo esto último a tu interpretación.
-
Aquí me refiero a los archivos Parquet almacenados en un sistema de archivos normal, los data lakes son otra historia. ↩︎